Blog
Does AI have a place in trustworthy medicines information?
Dec 12, 2025
Philippe Michiels, gives his technical insight into how generative AI, utilising FHIR structured ePIs, could play a role in accessing trustworthy answers about medicines.


Philippe Michiels
Principal Architect, Datapharm
AI brings both promise and concern about enabling healthcare professionals and patients with reliable information on medicines. Aware of the potential, and also the guardrails that have to be put in place, we have been experimenting with a prototype tool using a large language model (LLM).
In a recent webinar hosted by Gravitate Health, we demonstrated how this tool could base its answers on information provided within fully structured ePIs (electronic Product Information). By standardising medicines information into these granular, machine‑readable formats, ePIs create the foundation for AI systems to deliver contextualised, explainable answers that are grounded in the latest approved data.
What is electronic Product Information (ePI)?
Electronic Product Information (ePI) is the regulator‑approved medicines information (such as the Summary of Product Characteristics, patient information leaflet, and/or labelling) published in a structured, digital format. It is adapted for handling in electronic format and dissemination via the web or digital platforms.
Before I go into what the ePI would look like, it’s important to bear in mind that LLMs are essentially language calculators – they interpret prompts to generate statistically plausible answers but they don’t truly understand whether the answers they are delivering contain the right or wrong information. Hence why you might see that some common chat- based tools can get a bit too creative when returning information.
The concern will always be that the AI tool will generate incorrect but plausible sounding responses that could be dangerous in a healthcare setting. This experiment is a simple demonstration and test of providing the AI tool with semantically correct granular information to guide the tool in using appropriate information to construct a response.
One of the main pitfalls of using these AI tools, especially with medicines information which is constantly changing, is that it’s not always sourcing the most up-to-date information. Here’s a simple example of how these tools can fall short (I’ve only recently asked the below):

Therefore, if you want more reliable answers about regulated information on medicines, there needs to be a way of ensuring that both:
- the LLM understands how the information is structured, and
- the dataset is up-to-date.
When your SmPC is document-based, a) cannot be achieved, but if it’s fully structured, this makes life very different. ePIs, while based on structured medicines information such as SmPCs, will remain up-to-date, thus negating the issue of b).
Until recently, within the Gravitate Health workshops we’d been working with ePI types 1-4 which, despite being an evolution in the structure of medicine product information, are strictly still document-based.
What we need to make it work
ePI type 5 is more about fragments, and virtually every piece of information you can think of would be structured. This would be a dream to work with, however ePI type 3 has most of the extra resources needed for an LLM to pull the correct information.
We also need answers which are explainable. This means that when the tool used by a healthcare professional confidently and emphatically returns its answer, we need it to explain itself with the reference source.
The model for explainable answers
If we were to send the full SmPC to the LLM directly, that’s really too much context for it to digest and provide a suitable answer on. So the AI tool would need to know how to query the latest data and go to the LLM with that more filtered context.
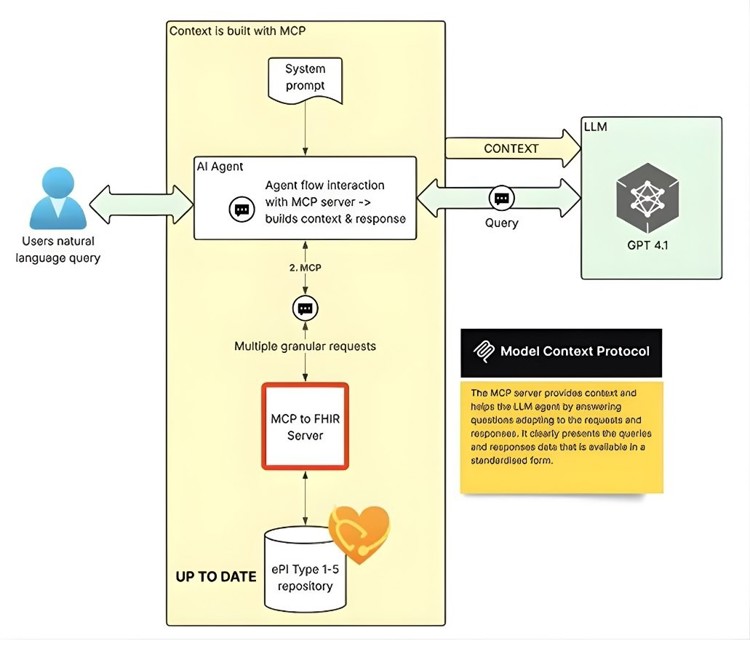
The tool we have been testing out is based on a MCP (Model context protocol) server, and makes the data easier to ingest and interpret. It sits on top of a FHIR server, which means it is taking the FHIR-structured data. This method has a few benefits:
- It has access to passive data sources for context, so it can supply additional contextual information (e.g. technical terminologies used in healthcare, documentation, or images) to enrich the AI tool’s responses.
- The MCP server makes AI answers explainable by keeping a record of what information has been requested, and ensures transparency in how it’s retrieved.
- It can provide the LLM with pre-built instruction templates on how to use it, with some example prompts.
In short, the context is optimised to answer the query. Potential issues around model training (to ensure the answers are up-to-date) are negated as the FHIR data it’s pulling from is the latest available resource. Another helpful element of this method is the workflow that can be followed in order to dig out the information.
How this looks in practice
In this demonstration, we ingested a mock ePI medicine, and used Claude AI as the AI agent.

As mentioned above, we know that this prototype should make its answers explainable - here we can see the tool working out its answer, making any specific targeted queries of the data, in from the ePI:
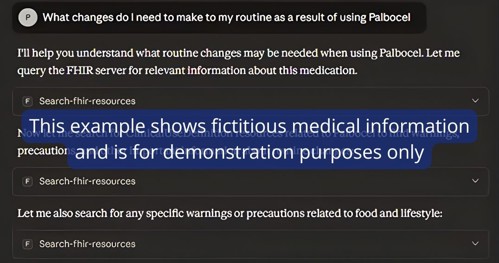

And based on this, it shows the result:

And it also tells us what it used from the FHIR ePI, based on the above query:

Here’s another example:
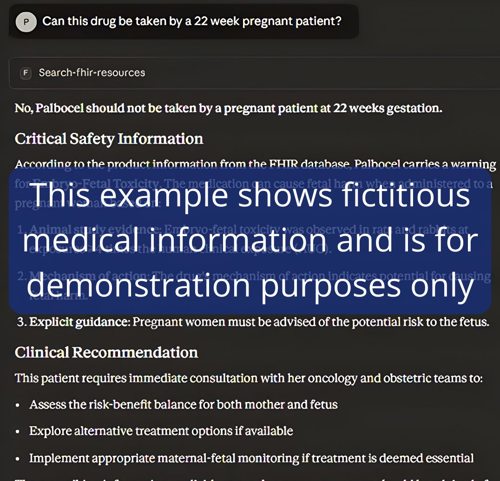
Is this achievable? The challenges ahead
All this would need a well-structured ePI. Type 3, 4 or 5, which meets this need, would need to be extremely granular - for a whole ePI, that would be a large number of data elements and, for every licensed medicine on the market, this is no mean feat.
Currently these extra granular data elements exist but are not yet freely exchanged between industry, compendia and regulators. The other challenge is regulation. We will need to ensure that appropriate guardrails are in place (e.g. if the question goes outside of its data knowledge, how can we help it be ‘honest’), and in order to pass regulation and the Code of practice, we’ll need to have highly effective collaboration to push adoption in the future – culturally, this may be easier in some countries than in others.
Other AI techniques exist and their deployment will depend on the use cases. The MCP approach described here is generalised for use with a broad range of different types of agentic systems and satisfies applications that require access to a large range of product data. Other approaches require more direct integration into the models and may suit lower latency requirements.
Learn more about ePI’s role in the future of healthcare information
Because of their trustworthy source, structured ePIs are a means to transform access to medicines information, supporting healthcare professionals and patients in making informed decisions, and strengthening trust in digital healthcare tools.
Datapharm is part of the Gravitate Health project, which holds the mission to empower and equip Europeans with health information for active personal health management and adherence to treatment. The project includes working together to create valid use cases with structured ePIs, based on FHIR (Fast Healthcare Interoperability Resources).
Watch the full replay from Gravitate Health’s ‘Open E2E ePI Community Webinar’: Watch on YouTube
If you would like to learn more about working with a tech partner on structured medicines information, get in touch with our team today: